Speech Recognition model API¶
About The Project¶
Our speech to text interface enables you to accurately convert speech into text using an API powered by deep learning neural network algorithms for automatic speech recognition (ASR).
This is enabled to provide the following features:
-
Speech to text transcription support for a growing list of indic languages.
-
Transcribe your content in real time from stored files or audio bytes.
-
Generate subtitle or transcript for your audios as per your choice of output.
-
Support for various audio formats like WAV, MP3, PCM.
-
Speech-to-Text accurately punctuates transcriptions (e.g., commas, question marks, and periods).
-
[beta]Enables transcription optimized for domain-specific quality requirements associating domain models in backend.
The Developer documentation provides you with a complete set of guidelines which you need to get started with:
- Architecture overview
- API reference
- Developer Documentation
- Contribute to this project
- Tutorials Reference
Architecture Overview¶
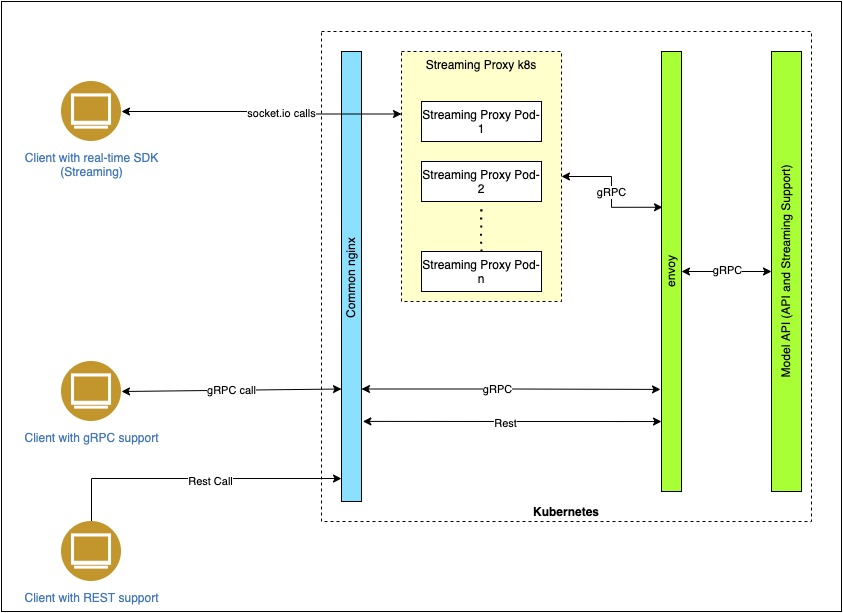
The logical architecture here is built with a grpc server hosting our speech recognition models and dependencies, which can be run in any environment or docker. With gRPC, we can define our service once in a proto file and generate clients and servers in any of gRPC’s supported languages. Which in turn can be run in environments ranging from servers inside a large data center to your own tablet. All the complexity of communication between different languages and environments is handled for you by gRPC. We also get all the advantages of working with protocol buffers, including efficient serialization, a simple IDL, and easy interface updating. You can read about gRPC in the gRPC doc.
Apart from using gRPC stubs, we have added the support for REST calls to the gRPC server via envoy as API gateway. Once you specify special mapping rules, API Gateway translates RESTful JSON over HTTP into gRPC requests. This means that you can deploy a gRPC server with envoy and call its API using a gRPC or JSON/HTTP client, giving you much more flexibility and ease of integration with other systems.
API reference¶
Our API has predictable resource-oriented URLs, accepts form-encoded request bodies, returns JSON-encoded responses, and uses standard HTTP response codes, authentication, and verbs.
Supported Endpoints
| Endpoint | Purpose |
|---|---|
| recognize_audio | Streaming Endpoint. |
| punctuate | Punctuation endpoint for a given text. |
| recognize | Inferencing from a audio URL or bytes. |
More details are available here.
Authentication and Authorization
We do not have any authentication or authorization layer built into API. So you can choose any mechanism or enhance the API at your convenience to support it.
Errors
Our API uses HTTP response codes to indicate the success or failure of an API request.
| Status | Meaning | Description |
|---|---|---|
| 200 | OK | Everything worked as expected. |
| 400 | Bad Request | The request was unacceptable, often due to missing a required parameter. |
| 401 | Unauthorized | No valid API key provided. |
| 402 | Request Failed | The parameters were valid but the request failed. |
| 403 | Forbidden | The API key doesn't have permissions to perform the request. |
| 404 | Not Found | The requested resource doesn't exist. |
| 409 | Conflict | The request conflicts with another request (perhaps due to using the same idempotent key). |
| 429 | Too Many Requests | Too many requests hit the API too quickly. We recommend an exponential backoff of your requests. |
| 50X | Server Errors | Something went wrong on Stripe's end. (These are rare.) |
Developer Documentation¶
API and all dependent components are open sourced.
Tutorials Reference¶
- https://www.youtube.com/watch?v=2Jm5cN_Wd00&list=PLA97EDXt7HiUF56ueLGPk3WixYmKC4QGe&index=23
- https://www.youtube.com/watch?v=wCASFbughCw&list=PLA97EDXt7HiUF56ueLGPk3WixYmKC4QGe&index=24
Contributing¶
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
License¶
Distributed under the [MIT] License. See LICENSE for more information.
Git repository¶
https://github.com/Open-Speech-EkStep/speech-recognition-open-api.git
Contact¶
Connect with community on Gitter
Project Link: https://github.com/Open-Speech-EkStep/speech-recognition-open-api.git