Speech Recognition Streaming Service¶
Our speech to text interface enables you to accurately convert speech into text using an API powered by deep learning neural network algorithms for automatic speech recognition (ASR). To know more, Click Here
This Streaming API provides an interface to accept chunks of continuous audio stream that can be transcribed in realtime to text by using the above mentioned speech to text interface.
This service provides the following features:
-
Speech to text transcription support for a growing list of indic languages.
-
Transcribe your content in real time from stored files or audio bytes.
The Developer documentation provides you with a complete set of guidelines which you need to get started with.
Table of Contents¶
- Architecture overview
- Components
- Quick Start
- Tips
- Contribute to the project
- License
- Git Repositories
- Contact
Architecture Overview¶
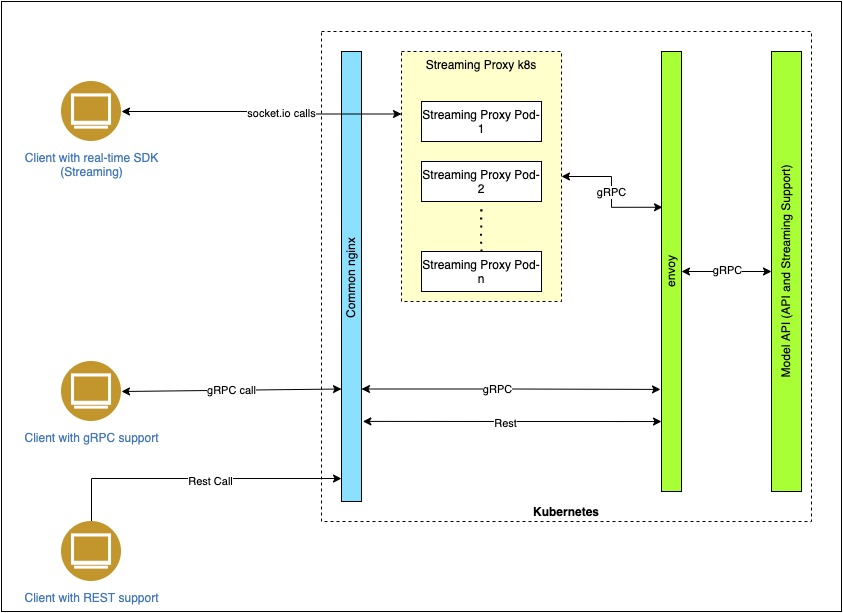
Components¶
This service consists of two main components.
- GRPC client
- GRPC server
It also contains two plugin/support components.
- Proxy service.
- Browser client sdk.
GRPC Server¶
In this streaming service, the grpc server provides a method that supports bi-directional streaming to allow users to stream audio bytes continuously and get stream of text as output. The audio bytes provided in the stream are pre-processed and provided to the model (Speech to text model) for inferencing. As a result, we get a continuous stream of text as output for the given audio stream. This server is capable of handling multiple grpc clients and provide continuous streams of output.
This grpc server is written in python programming language.
For more info on grpc servers bi-directional streaming, refer here.
This grpc server is available in the following Github Link
GRPC Client¶
The grpc client allows users/other platforms to connect to the grpc server through a channel and call the required RPC methods.Grpc clients are available in multiple programming languages like python, nodejs, java, etc.
In this streaming service, we are using nodejs grpc client to connect with the streaming service.
To allow users to connect to our grpc server from browsers, we have created a proxy service which uses socket.io to maintain two way connections so that audio can be streamed from the user using browsers and send it to the grpc server from the proxy using nodejs grpc client.
Proxy Service¶
This service allows browser-users/web-applications to stream audios to the grpc server and provides the streaming transcriptions back to the browser-users/web-applications.
It is available in the following Github Link.
Reason for using proxy component¶
To use grpc client in browsers, we need to use a library called grpc-web. To know more about why grpc-web is needed, refer here.
But, in the grpc-web library, there was no support for bi-directional streaming currently when this project was developed. So we have adopted to create our proxy service to create a realtime processing environment.
The proxy service is developed using nodejs.
The components of the proxy service are:
- Socket.io server
- Nodejs Grpc client
Socket.io server¶
This socket.io server create events and listens to the incoming audio streams and provides the received audio streams to the grpc client. Once the socket.io server receives the stream of transcriptions from the nodejs grpc client, it will emit result events to the socket.io client connected to this server.
Nodejs Grpc client¶
This nodejs grpc client creates a channel with the grpc server for each incoming user and streams the audio through the RPC method. Once the RPC method returns the stream of transcriptions, it will provide it to the socket.io server.
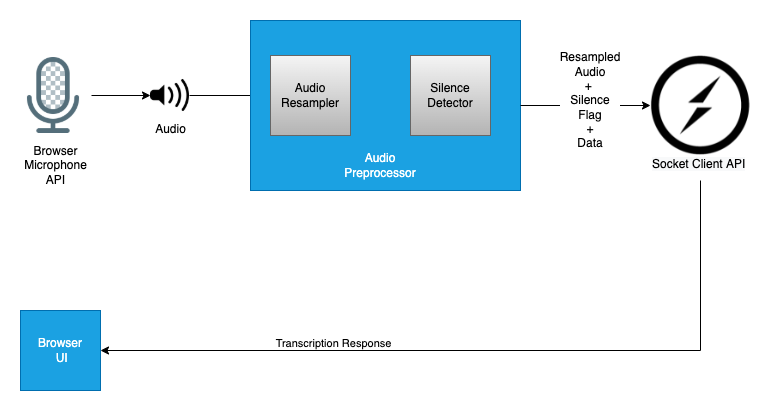
Browser Client SDK¶
To connect to the proxy and stream audio, we can use a socket.io client. Since we need to do a lot of pre-processing and maintain the socket events needed, we have created a client sdk available as a npm library.
This client sdk can be imported in any node related frameworks such as React, angular, etc. It will provide methods to connect and stream audio to the proxy service.
To know more, refer to this Github link.
To get started with this Browser client sdk, refer to the Readme in the above github link.
Quick Start¶
Pre-requisites¶
- Download and install
docker. - Download and install
git. - Download latest stable version of
nodejs.
Streaming server setup¶
-
Pre-built docker images are hosted on gcr.io/ekstepspeechrecognition/speech_recognition_model_api. We do not follow the latest tag, so you have to use a specific tag. You can pull the image using the command given below:
docker pull gcr.io/ekstepspeechrecognition/speech_recognition_model_api:3.2.25 -
Create a directory deployed_models using the command:
mkdir deployed_models - Inside deployed_models folder, create a folder for each language. eg:
mkdir hindi - Download asr fine-tuned models and language models for the languages you need from the link given here.
- Directory structure of
deployed_models/:
.
|-- hindi
| |-- hindi_infer.pt
| |-- dict.ltr.txt
| |-- lexicon.lst
| |-- lm.binary
|-- english
| |-- english_infer.pt
| |-- dict.ltr.txt
| |-- lexicon.lst
| |-- lm.binary
|-- model_dict.json
- The contents of the
model_dict.jsonfile mentioned in above step should contain the path of the model files. For example:
{
"en": {
"path": "/english/english_infer.pt",
"enablePunctuation": true,
"enableITN": true
},
"hi": {
"path": "/hindi/hindi_infer.pt",
"enablePunctuation": true,
"enableITN": true
}
}
Note: enablePunctuation flag is used if the transcription from the model needs to be punctuated. enabledITN flag is used if the inverse text normalization is needed for the transcripts from the model. Streaming text from server will not have the response punctuated or ITN applied. It needs to be done separately. Refer, streaming client sdk readme for more details.
- Run the streaming grpc server using the following command:
docker run -itd -p 50051:50051 --env gpu=True --env languages=['en'] --gpus all -v /home/user/project/deployed_models/:/opt/speech_recognition_open_api/deployed_models/ gcr.io/ekstepspeechrecognition/speech_recognition_model_api:3.2.25
- This will keep the streaming grpc server up and running in port
50051as mentioned in the above docker command.
Streaming proxy service setup¶
- Clone the proxy service from github:
git clone https://github.com/Open-Speech-EkStep/speech-recognition-open-api-proxy.git
- Run
cd speech-recognition-open-api-proxy. - Install the project dependencies:
npm i. - Configure the
language_map.jsonfile (inproject-root-foldereg: /users/node/speech-recognition-open-api-proxy/language_map.json), so that it points to the grpc server which is hosted in port50051in the above steps. For example:
{
"<ip-address/host>:<port>": [
"hi",
"en"
],
"localhost:50051": [
"ta",
"te"
]
}
- Set the folder path of language_map.json as env variable
config_base_path="<project-root-folder>"(eg: /users/node/speech-recognition-open-api-proxy). - Run the proxy service:
npm start. - The proxy service will be up and running in port
9009.
Website UI setup with Streaming client sdk¶
- To create a streaming web ui, clone the below repository from github:
git clone https://github.com/Open-Speech-EkStep/speech-recognition-open-api-client.git
- Run
cd speech-recognition-open-api-client && cd examples/react-example. - Install the project dependencies:
npm i. - Open the file :
src/App.js. - In this file, in handleStart() method in line 25 and 26, modify the url and language as you need: example
const url = 'http://localhost:9009'; // url of the proxy service
const language = 'hi'; // this can be en, gu depends on what models you have hosted.
- Save and Close the file once the changes are done.
- Run the service using
npm start. - This will open a browser where you can click on the start button and start speaking. For every pause you provide, you will be getting a streamed transcription output.
Tips¶
- In step 7, multiple languages can be given in one docker container by doing the following for languages env variable.
--env languages=['en', 'hi']
- Multiple docker containers can be created with different language sets and they can all be accessed by using the proxy service. For example, docker container1 is hosted with en,hi on port 50051 and docker container2 is hosted with ta,te on port 50052, then
language_config.jsonfile content will be as follows:
{
"localhost:50051": [
"hi",
"en"
],
"localhost:50052": [
"ta",
"te"
],
}
- Port of the proxy service can be changed
PORTenv variable.
Contribute to the project¶
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated.
- Fork the Project.
- Create your Feature Branch (
git checkout -b feature/AmazingFeature). - Commit your Changes (
git commit -m 'Add some AmazingFeature'). - Push to the Branch (
git push origin feature/AmazingFeature). - Open a Pull Request.
License¶
Distributed under the [MIT] License. See LICENSE for more information.
Git repositories¶
- Streaming Server : https://github.com/Open-Speech-EkStep/speech-recognition-open-api.git.
- Proxy Service: https://github.com/Open-Speech-EkStep/speech-recognition-open-api-proxy.git.
- Client SDK: https://github.com/Open-Speech-EkStep/speech-recognition-open-api-client.git.
Contact¶
Connect with community on Gitter.