Data Collection Pipeline¶
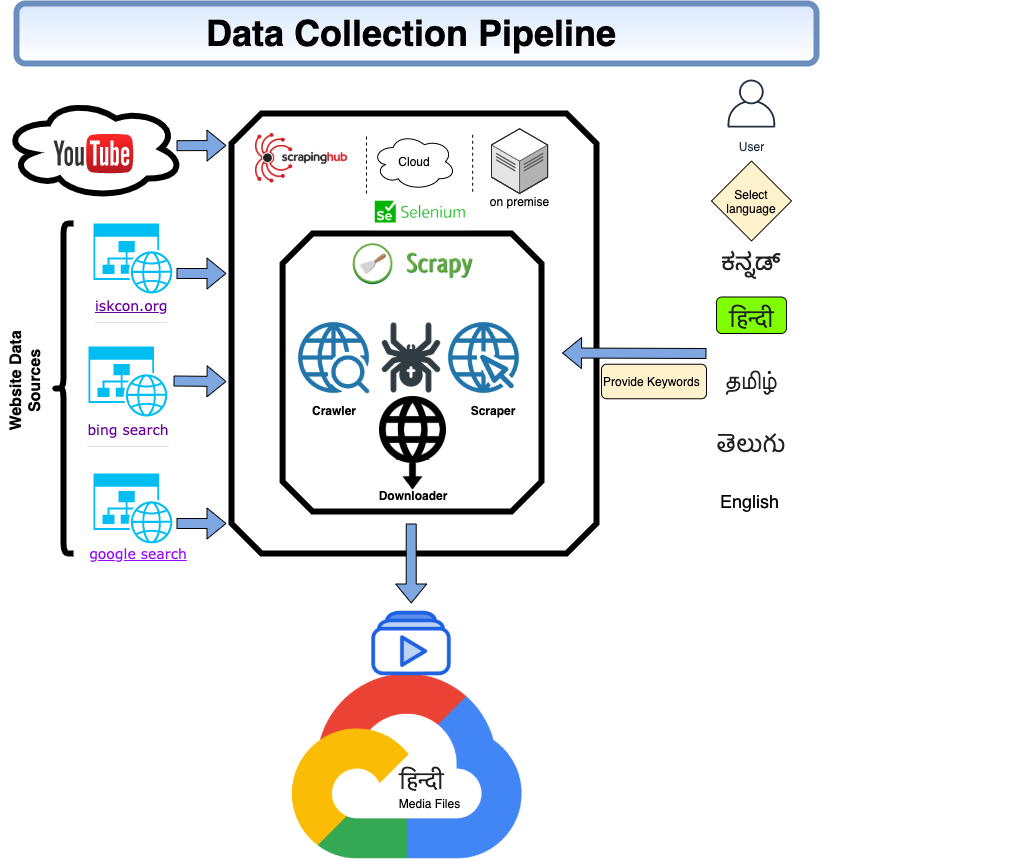
About The Project¶
This is downloading framework that is extensible and allows the user to add new source without much code changes. For each new source user need to write a scrapy spider script and rest of downloading and meta file creation is handled by repective pipelines. And if required user can add their custom pipelines. This framework automatically transfer the downloaded data to a Google cloud bucket automatically. For more info on writing scrapy spider and pipeline one can refer to the documentation. Data Collection Pipeline’s developer documentation is meant for its adopters, developers and contributors.
The developer documentation helps you to get familiar with the bare necessities, giving you a quick and clean approach to get you up and running. If you are looking for ways to customize the workflow, or just breaking things down to build them back up, head to the reference section to dig into the mechanics of Data Collection Pipeline.
Data Collection Pipeline is based on an open platform, you are free to use any programming language to extend or customize it but we prefer to use python to perform smart scraping.
The Developer documentation provides you with a complete set of guidelines which you need to:
- Install Data Collection Pipeline
- Configure Data Collection Pipeline
- Customize Data Collection Pipeline
- Extend Data Collection Pipeline
- Contribute to Data Collection Pipeline
Built With¶
We have used scrapy as the base of this framework. * Scrapy
Summary¶
This summary mentions the key advantages and limitations of this smart crawler service.
Youtube Crawler
- Key Points and Advantages:
- Get language relevant channels from YouTube and download videos from them.(70%-80% relevancy with language - based on Manual Analysis)
- Can fetch channels with Creative Commons video and download the videos in them as well.(70% relevancy with language)
- Can download using file mode(manually filled with video Ids) or channel mode.
- Youtube-dl can fetch N number of videos from a channel and download them.
- YouTube crawler downloads files at a rate of maximum of 2000 hours per day and minimum of 800 hours per day.
- Youtube crawler is more convenient and it’s a main source of Creative Commons data that can be accessed easily.
- It can be deployed in cloud service called zyte used for scraping/crawling.
- License information of videos are available in metadata.
- Limitations:
- Youtube-api cannot return more than 500 videos per channel.(when using YOUTUBE_API mode in configuration)
- Youtube-api is restricted to 10000 tokens per day in free mode.
- 10000 tokens can be used to get license info of 10000 videos.(in any mode)
- 10000 tokens can be used to get 5000 channels.(in YOUTUBE_API mode)
- Youtube-dl can be used to get all videos freely.(in YOUTUBE_DL mode)
- Cannot fetch data from specific playlist. (Solution: Fetch videos Ids of a playlist using YouTube-dl and put them in a file and download in file mode.)
- Rare cases in which you might get Too many requests error from Youtube-DL. (Solution: Rerun the application with same sources.)
- Cannot download videos which require user information and private videos.
Web Crawler
- Key Points and Advantages:
- Web crawler can download specific language audio but with around 50 - 60% relevance.
- Web crawler downloads files at a rate of at least 2000 hours per day.
- It is a faster means of downloading data.
- Creative Commons license of videos can be identified if available while crawling websites.
- Limitations:
- Web crawler is not finely tuned yet, so downloaded content might have low language relevance.
- It cannot be deployed in zyte service free accounts and can be only deployed in zyte service paid accounts where docker container creation can be customised.
- License information of videos in web crawler cannot be automatically identified but requires some manual intervention.
Getting Started¶
To get started install the prerequisites and clone the repo to machine on which you wish to run the framework.
Prerequisites¶
-
Install
ffmpeglibrary using commands mentioned below.-
For any linux based operating system (preferred Ubuntu):
sudo apt-get install ffmpeg -
For Mac-os:
brew install ffmpeg -
Windows user can follow installation steps on https://www.ffmpeg.org
-
-
Install Python Version = 3.6
-
Get credentials from google developer console for google cloud storage access.
Installation¶
-
Clone the repo using
git clone https://github.com/Open-Speech-EkStep/data-acquisition-pipeline.git -
Go inside the directory
cd data-acquisition-pipeline -
Install python requirements
``` pip install -r requirements.txt
-
Install gcloud utils
Download from: https://cloud.google.com/sdk/docs/install#linux > gcloud init
Usage¶
This framework allows the user to download the media file from a websource(youtube, xyz.com, etc) and creates the respective metadata file from the data that is extracted from the file.For using any added source or to add new source refer to steps below.It can also crawl internet for media of a specific language. For web crawling, refer to the web crawl configuration below.
Common configuration steps:¶
Setting credentials for Google cloud bucket¶
You can set credentials for Google cloud bucket in the credentials.json add the credentials in given manner It can be found in the project root folder.
{"Credentials":{ YOUR ACCOUNT CREDENTIAL KEYS }}
Note: All configuration files can be found in the following path data-acquisition-pipeline/data_acquisition_framework/configs/
Bucket configuration¶
Bucket configurations for data transfer in storage_config.json
"bucket": "ekstepspeechrecognition-dev", Your bucket name
"channel_blob_path": "scrapydump/refactor_test", Path to directory where downloaded files is to be stored
"archive_blob_path": "archive", Folder name in which history of download is to be maintained
"channels_file_blob_path": "channels", Folder name in which channels and its videos are saved
"scraped_data_blob_path": "data_to_be_scraped" Folder name in which CSV for youtube file mode is stored
Note:
1. The scraped_data_blob_path folder should be present inside the channel_blob_path folder.
2. The CSV file used in file mode of youtube and its name must be same as source_name given above.
3. (only for datacollector_urls and datacollector_bing spiders) To autoconfigure language parameter to channel_blob_path from web_crawler_config.json, use <language> in channel_blob_path.
"eg: for tamil : data/download/<language>/audio - this will replace <language> with tamil."
4. The archive_blob_path and channels_file_blob_path are folders that will be autogenerated in bucket with the given name.
Metadata file configurations¶
Metadata file configurations in config.json
mode: 'complete' This should not be changed
audio_id: null If you want to give a custom audio id add here
cleaned_duration: null If you know the cleaned duration of audio add here
num_of_speakers: null Number of speaker present in audio
language: Hindi Language of audio
has_other_audio_signature: False If audio has multiple speaker in same file (True/False)
type: 'audio' Type of media (audio or video)
source: 'Demo_Source' Source name
experiment_use: False If its for experimental use (True/False)
utterances_files_list: null
source_website: '' Source website url
experiment_name: null Name of experiment if experiment_use is True
mother_tongue: null Accent of language(Bengali, Marathi, etc...)
age_group: null Age group of speaker in audio
recorded_state: null State in which audio is recorded
recorded_district: null District of state in which audio is recorded
recorded_place: null Recording location
recorded_date: null Recording date
purpose: null Purpose of recording
speaker_gender: null Gender of speaker
speaker_name: null Name of speaker
Note:
1. If any of the field info is not available keep its value to null
2. If speaker_name or speaker_gender is given then that same will be used for all the files in given source
Youtube download configurations¶
- You can set download mode [file/channel] in youtube_pipeline_config.py In file mode you will store a csv file whose name must be same as source name in scraped_data_blob_path. csv must contain urls of youtube videos, speaker name and gender as three different columns. Urls is a must field. You can leave speaker name and gender blank if data is not available.
mode = 'file' # [channel,file]
Given below is the structure of csv.video_url,speaker_name,speaker_gender https://www.youtube.com/watch?v=K1vW_ZikA5o,Ram_Singh,male https://www.youtube.com/watch?v=o82HIOgozi8,John_Doe,male ... - Common configurations in youtube_pipeline_config.py Possible values for youtube_service_to_use: (YoutubeService.YOUTUBE_DL, YoutubeService.YOUTUBE_API)
# Common configurations "source_name": "DEMO", This is the name of source you are downloading batch_num = 1 Number of videos to be downloaded as batches youtube_service_to_use = YoutubeService.YOUTUBE_DL This field is to choose which service to use for getting video information only_creative_commons = False Should Download only creative commons(True, False) - File mode configurations in youtube_pipeline_config.py
# File Mode configurations file_speaker_gender_column = 'speaker_gender' Gender column name in csv file file_speaker_name_column = "speaker_name" Speaker name column name in csv file file_url_name_column = "video_url" Video url column name in csv file license_column = "license" Video license column name in csv file - channel mode configuration in youtube_pipeline_config.py
# Channel mode configurations channel_url_dict = {} Channel url dictionary (This will download all the videos from the given channels with corresponding source names) Note: 1. In channel_url_dict, the keys must be the urls and values must be their channel names 2. To get list of channels from youtube API, channel_url_dict must be empty
Youtube API configuration¶
- Automated Youtube fetching configuration in youtube_api_config.json
# Youtube API configurations "language" : "hindi", Type of language for which search results are required. "language_code": "hi", Language code for the specified language. "keywords":[ The search keywords to be given in youtube API query "audio", "speech", "talk" ], "words_to_ignore":[ The words that are to be ignored in youtube API query "song", "music" ], "max_results": 20 Maximum number of channels or results that is required.
Web Crawl Configuration¶
- web crawl configuration in web_crawl_config.json (Use this only for datacollector_bing and datacollector_urls spider)
"language": "gujarati", Language to be crawled "language_code": "gu", Language code for the specified language. "keywords": [ Keywords to query "talks audio", "audiobooks", "speeches", ], "word_to_ignore": [ Words to ignore while crawling "ieeexplore.ieee.org", "dl.acm.org", "www.microsoft.com" ], "extensions_to_ignore": [ Formats/extensions to ignore while crawling ".jpeg", "xlsx", ".xml" ], "extensions_to_include": [ Formats/extensions to include while crawling ".mp3", ".wav", ".mp4", ], "pages": 1, Number of pages to crawl "depth": 1, Nesting depth for each website "continue_page": "NO", Field to continue/resume crawling "last_visited": 200, Last visited results count "enable_hours_restriction": "YES", Restrict crawling based on hours of data collected "max_hours": 1 Maximum hours to crawl
Adding new spider¶
As we already mentioned our framework is extensible for any new source. To add a new source user just need to write a spider for that source.
To add a spider you can follow the scrapy documentation or you can check our sample spider.
Running services¶
Make sure the google credentials are present in project root folder in credentials.json file.
Youtube spider in channel mode:¶
-
In
data_acqusition_framework/configs, do the following:-
Open
config.jsonand changelanguageandtypeto your respective use case. -
Open
storage_config.jsonand changebucketandchannel_blob_pathto your respective gcp paths.(For more info on these fields, scroll above to Bucket configuration) -
Open
youtube_pipeline_config.pyand change mode to channel(eg: mode='channel')
-
-
There are two ways to download videos of youtube channels:
-
You can hardcode the channel url and channel name.
-
You can use youtube-utils service(youtube-dl/youtube data api) to fetch channels and its respective videos information.
-
-
To download by hardcoding the channel urls, do the following:
-
Open
data_acqusition_framework/configs/youtube_pipeline_config.pyand do the following: -
Add the channel_urls and its names in
channel_url_dictvariable.eg. channel_url_dict = { "https://www.youtube.com/channel/1": "channel_name_a", "https://www.youtube.com/channel/2":"channel_name_b" } -
Set
youtube_service_to_usevariable value to eitherYoutubeService.YOUTUBE_DLorYoutubeService.YOUTUBE_APIfor collecting video info. -
If
YoutubeService.YOUTUBE_APIis chosen, then get APIKEY for youtube data api from google developer console and store it in a file called.youtube_api_keyin project root folder. Generate.youtube_api_keyfrom -
From the project root folder, run the following command:
scrapy crawl datacollector_youtube --set=ITEM_PIPELINES='{"data_acquisition_framework.pipelines.youtube_api_pipeline.YoutubeApiPipeline": 1}' -
This will start fetching the videos from youtube for the given channels and download them to bucket.
-
-
To download by using youtube-utils service, do the following:
-
Open
data_acqusition_framework/configs/youtube_pipeline_config.pyand do the following:- Assign
channel_url_dict = {}(If not empty, will not work). - Set
youtube_service_to_usevariable value to eitherYoutubeService.YOUTUBE_DLorYoutubeService.YOUTUBE_APIfor collecting video info. - If
YoutubeService.YOUTUBE_APIis chosen, then get APIKEY for youtube data api from google developer console and store it in a file called.youtube_api_keyin project root folder.
- Assign
-
Open
data_acqusition_framework/configs/youtube_api_config.jsonand change the fields to your requirements.(For more info: check above in Youtube api configuration) -
From the project root folder, run the following command:
scrapy crawl datacollector_youtube --set=ITEM_PIPELINES='{"data_acquisition_framework.pipelines.youtube_api_pipeline.YoutubeApiPipeline": 1}' -
This will start fetching the videos from youtube for the given channels and download them to bucket.
-
Youtube spider in file mode:¶
-
In
data_acqusition_framework/configs, do the following:-
Open
config.jsonand changelanguageandtypeto your respective use case. -
Open
storage_config.jsonand changebucketandchannel_blob_pathto your respective gcp paths.(For more info on these fields, scroll above to Bucket configuration) -
Open
youtube_pipeline_config.pyand do the following:- change
modetofile(eg: mode='file'). - change
source_nameto your requirement so that videos get downloaded to that folder in google storage bucket.
- change
-
-
Next Steps:
-
Create a file in the following format:
eg.
source_name.csvwith content (license column is optional): Heresource_nameinsource_name.csvis the name you gave in youtube_pipeline_config.py file. It should be the same.video_url,speaker_name,speaker_gender,license https://www.youtube.com/watch?v=K1vW_ZikA5o,Ram_Singh,male,Creative Commons https://www.youtube.com/watch?v=o82HIOgozi8,John_Doe,male,Standard Youtube ... -
Now to upload this file to google cloud storage do the following:
- Open the
channel_blob_pathfolder that you gave instorage_config.jsonand create a folder there nameddata_to_be_scraped. - Upload the file that you created with previous step to this folder.
- Open the
-
From the project root folder, run the following command:
scrapy crawl datacollector_youtube --set=ITEM_PIPELINES='{"data_acquisition_framework.pipelines.youtube_api_pipeline.YoutubeApiPipeline": 1}' -
This will start fetching the videos mentioned in the file from youtube and download them to bucket.
-
Bing Spider¶
-
Configure
data_acquisition_framework/configs/web_crawl_config.jsonfor your requirements. -
Starting datacollector_bing spider with audio pipeline.
-
From project root folder, run the following:
scrapy crawl datacollector_bing
-
Urls Spider¶
-
Configure
data_acquisition_framework/configs/web_crawl_config.jsonfor your requirements. -
Starting datacollector_urls spider with audio pipeline.
- Make sure to put the urls to crawl in the
data_acquisition_framework/urls.txt. -
From project root folder, run the following:
scrapy crawl datacollector_urls
- Make sure to put the urls to crawl in the
Selenium google crawler¶
-
It is capable of crawling search results of google for a given language and exporting them to urls.txt file. This urls.txt file can be used with datacollector_urls spider to crawl all the search results website and download the media along with their metadata.
-
A specified Readme can be found in selenium_google_crawler folder. Readme for selenium google crawler
Selenium youtube crawler for file mode and api mode¶
-
It is capable of crawling youtube videos using youtube api or from a list of files with youtube video ids provided with channel name as filename.
-
A specified Readme can be found in selenium_youtube_crawler folder. Readme for selenium youtube crawler
Tutorials Reference¶
- https://www.youtube.com/watch?v=VPZfntRpNqQ&list=PLA97EDXt7HiUF56ueLGPk3WixYmKC4QGe&index=10
- https://www.youtube.com/watch?v=iySYi3Uwp1U&list=PLA97EDXt7HiUF56ueLGPk3WixYmKC4QGe&index=12
Contributing¶
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
License¶
Distributed under the [XYZ] License. See LICENSE for more information.
Git Repository¶
https://github.com/Open-Speech-EkStep/data-acquisition-pipeline
Contact¶
Connect with community on Gitter