Pretrained Models¶
We are releasing pretrained models in various Indic Languages. Please head over to this repo.
Table of contents¶
- Installation and Setup
- Directory Structure
- Data Description
- Usage
- For Language Model generation
- Tutorials Reference
- License
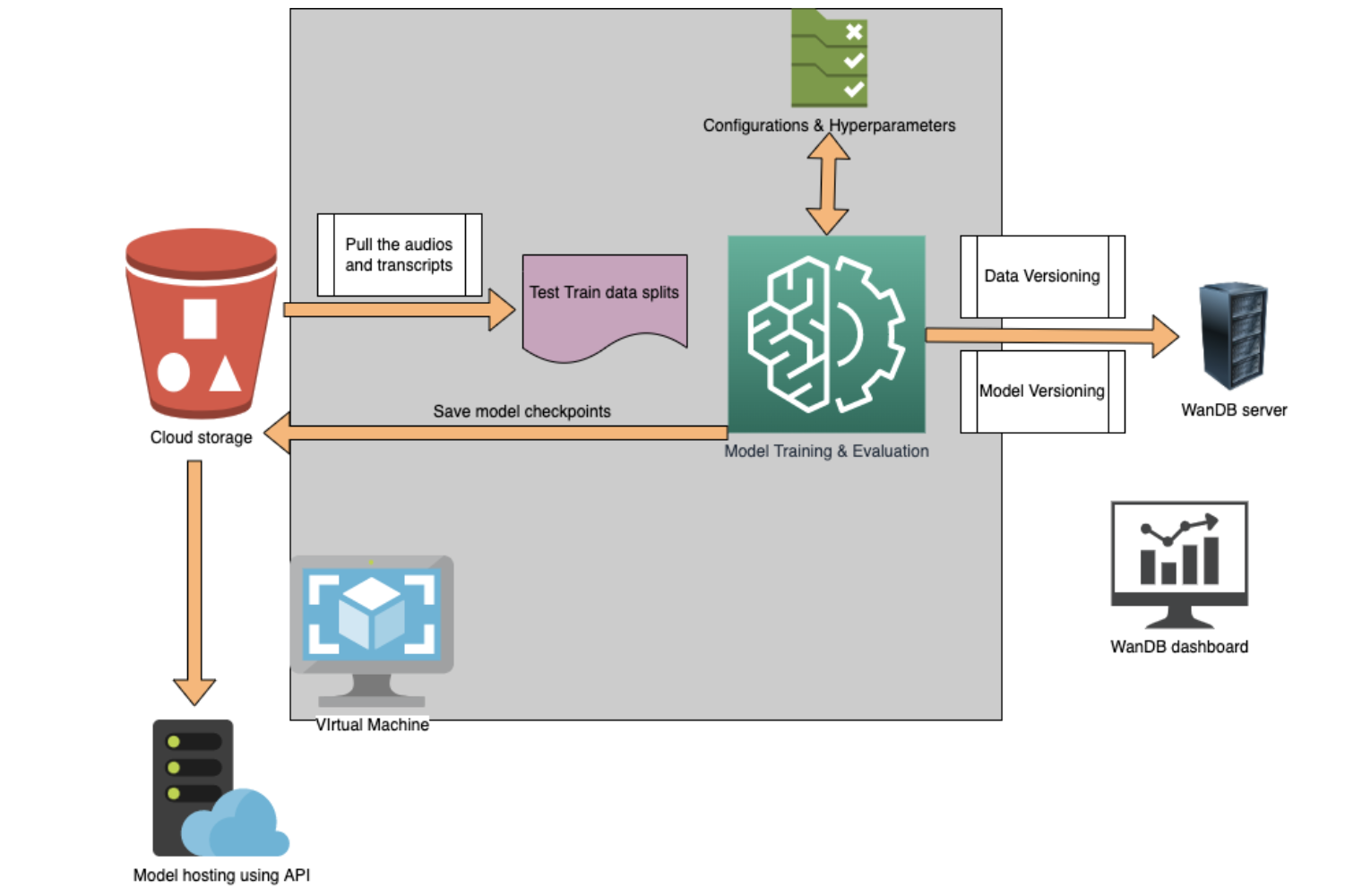
Model training Pipeline
Installation and Setup¶
git clone https://github.com/Open-Speech-EkStep/vakyansh-wav2vec2-experimentation.git
conda create --name <env_name> python=3.7
conda activate <env_name>
cd vakyansh-wav2vec2-experimentation
### Packages
pip install packaging soundfile swifter
pip install -r requirements.txt
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
### For fairseq setup(fairseq should be installed outside vakyansh-wav2vec2-experimentation repo)
cd ..
git clone -b ekstep-wav2vec2 https://github.com/Open-Speech-EkStep/fairseq.git
cd fairseq
pip install -e .
### install other libraries
### For Kenlm, openblas
cd ..
sudo apt-get install liblzma-dev libbz2-dev libzstd-dev libsndfile1-dev libopenblas-dev libfftw3-dev libgflags-dev libgoogle-glog-dev
sudo apt install build-essential cmake libboost-system-dev libboost-thread-dev libboost-program-options-dev libboost-test-dev libeigen3-dev zlib1g-dev libbz2-dev liblzma-dev
git clone https://github.com/kpu/kenlm.git
cd kenlm
mkdir -p build && cd build
cmake ..
make -j 16
cd ..
export KENLM_ROOT_DIR=$PWD
export USE_CUDA=0 ## for cpu
cd ..
### wav2letter
git clone -b v0.2 https://github.com/facebookresearch/wav2letter.git
cd wav2letter
git checkout b1d1f89f586120a978a4666cffd45c55f0a2e564
cd bindings/python
pip install -e .
Directory Structure¶
root-directory
.
|-- ./checkpoints
| |-- ./checkpoints/custom_model
| | `-- ./checkpoints/custom_model/
| |-- ./checkpoints/finetuning
| | `-- ./checkpoints/finetuning/
| `-- ./checkpoints/pretraining
| `-- ./checkpoints/pretraining/
|-- ./data
| |-- ./data/finetuning
| | `-- ./data/finetuning/
| |-- ./data/inference
| | `-- ./data/inference/
| |-- ./data/pretraining
| | `-- ./data/pretraining/
| `-- ./data/processed
| `-- ./data/processed/
|-- ./lm
| `-- ./lm/
|-- ./logs
| |-- ./logs/finetuning
| | `-- ./logs/finetuning/
| `-- ./logs/pretraining
| `-- ./logs/pretraining/
|-- ./notebooks
| `-- ./notebooks/
|-- ./results
| `-- ./results/
|-- ./scripts
| |-- ./scripts/data
| | `-- ./scripts/data/
| |-- ./scripts/parse_yaml.sh
| |-- ./scripts/finetuning
| | |-- ./scripts/finetuning/start_finetuning.sh
| | |-- ./scripts/finetuning/prepare_data.sh
| | `-- ./scripts/finetuning/README.md
| |-- ./scripts/lm
| | |-- ./scripts/lm/run_lm_pipeline.sh
| | `-- ./scripts/lm/README.md
| |-- ./scripts/pretraining
| | |-- ./scripts/pretraining/start_pretraining_base.sh
| | |-- ./scripts/pretraining/start_pretraining_large.sh
| | |-- ./scripts/pretraining/prepare_data.sh
| | `-- ./scripts/pretraining/README.md
| `-- ./scripts/inference
| |-- ./scripts/inference/infer.sh
| |-- ./scripts/inference/prepare_data.sh
| |-- ./scripts/inference/generate_custom_model.sh
| |-- ./scripts/inference/single_file_inference.sh
| `-- ./scripts/inference/README.md
|-- ./config
| |-- ./config/finetuning.yaml
| |-- ./config/pretraining_base.yaml
| |-- ./config/pretraining_large.yaml
| `-- ./config/README.md
|-- ./requirements.txt
|-- ./utils
| |-- ./utils/analysis
| | `-- ./utils/analysis/generate_wav_report_from_tsv.py
| |-- ./utils/prep_scripts
| | |-- ./utils/prep_scripts/dict_and_lexicon_maker.py
| | |-- ./utils/prep_scripts/labels.py
| | `-- ./utils/prep_scripts/manifest.py
| |-- ./utils/wer
| | |-- ./utils/wer/wer.py
| | `-- ./utils/wer/wer_wav2vec.py
| |-- ./utils/inference
| | |-- ./utils/inference/generate_custom_model.py
| | `-- ./utils/inference/single_file_inference.py
| `-- ./utils/lm
| |-- ./utils/lm/concatenate_text.py
| |-- ./utils/lm/make_lexicon_lst.py
| |-- ./utils/lm/generate_lm.py
| |-- ./utils/lm/clean_text.py
| `-- ./utils/lm/remove_duplicate_lines.py
`-- ./README.md
Data Description¶
- For Audio Files.
- Sample Rate [Hz] = 16000
- Channels = 'mono'
- Bit Rate [kbit/s] = 256
- Precision [bits] = 16
- Audio length should be less than 30 seconds otherwise it will be ignored during data preparation
- After scripts/finetuning/prepare_data.sh is run, analysis will be generated which can be used to tune min/max_sample_size in the config files
- For Text Files
- Corresponding text file of each audio file must be on the same directory as its audio
- Text file should not contain any punctuation characters
- Check dict.ltr.txt file generated after prepare_data so that it does not contain any foreign language character
- For Language Model
- Character set of text used for language model should be same as character set used for training
- Sample code for cleaning text file for english language is given here clean_text.py
- Sample code for removing duplicate line from text file is given here remove_duplicate_lines.py
Usage¶
For Pretraining¶
Edit the path to data in the scripts/pretraining/prepare_data.sh file. To prepare the data:
$ cd scripts/pretraining
$ bash prepare_data.sh
$ bash start_pretraining_base.sh
For Finetuning¶
Edit the path to data in the scripts/finetuning/prepare_data.sh file. To prepare the data:
$ cd scripts/finetuning
$ bash prepare_data.sh
$ bash start_finetuning.sh
Refer this for finetuning parameters.
For Inference¶
Edit the path to data in the scripts/inference/prepare_data.sh file. To prepare the test data run:
$ cd scripts/inference/
$ bash prepare_data.sh
$ bash infer.sh
For Single File Inference¶
To generate custom model, run:
$ cd scripts/inference
$ bash generate_custom_model.sh
$ bash single_file_inference.sh
For Language Model generation¶
Edit the run_lm_pipeline.sh variables as required, then run:
$ cd scripts/lm
$ bash run_lm_pipeline.sh
Domain specific Language Model generation¶
To add support for proper nouns or to generate any domain specific language model for a language:
- Collect proper nouns or domain specific text for a language.
- Process raw text using lm data preparation scripts:
- Normalize raw text using normalize_file.py
- Clean text using clean_text.py
- Remove duplicate lines using remove_duplicate_lines.py
- Append proper nouns or domain specific text to existing text corpus for a specific language.
- Train Language model using generate_lm.sh on newly prepared text corpus.
Tutorials Reference¶
- https://www.youtube.com/watch?v=X-etVH5yvX4&list=PLA97EDXt7HiUF56ueLGPk3WixYmKC4QGe&index=15
- https://www.youtube.com/watch?v=IhN6pM15e6U&list=PLA97EDXt7HiUF56ueLGPk3WixYmKC4QGe&index=17
- https://www.youtube.com/watch?v=-U1mWvEjygs&list=PLA97EDXt7HiUF56ueLGPk3WixYmKC4QGe&index=19
- https://www.youtube.com/watch?v=Sv_rRFvNvrA&list=PLA97EDXt7HiUF56ueLGPk3WixYmKC4QGe&index=20
- https://www.youtube.com/watch?v=iKgOikAXLwM&list=PLA97EDXt7HiUF56ueLGPk3WixYmKC4QGe&index=21
License¶
fairseq(-py) is MIT-licensed. The license applies to the pre-trained models as well.