Text to Speech model API¶
About The Project¶
Text To Speech (TTS), also known as Speech Synthesis, is a process where text is converted into a human-sounding voice. TTS has been a popular choice for developers and business users alike when building IVR (Interactive Voice Response) solutions and other voice applications, as it accelerates time to production without having to record audio files with human voices. Using recorded files requires recording each message with a human voice, whereas TTS prompts can be dynamically generated from raw text.
Our TTS service can enable us to generate life-like speech synthesis in both male and female voices for an array of Indic languages like Hindi, Tamil,Malayalam, Kannada and many more.
API enable us to provide the following features:
-
Support for Indic only languages.
-
No software Installation required.
-
Cloud based robust API.
-
Two gender voices for every language.
-
Fast and easy integration.
-
Cross-platform capability.
The Developer documentation provides you with a complete set of guidelines which you need to get started with:
Architecture Overview¶
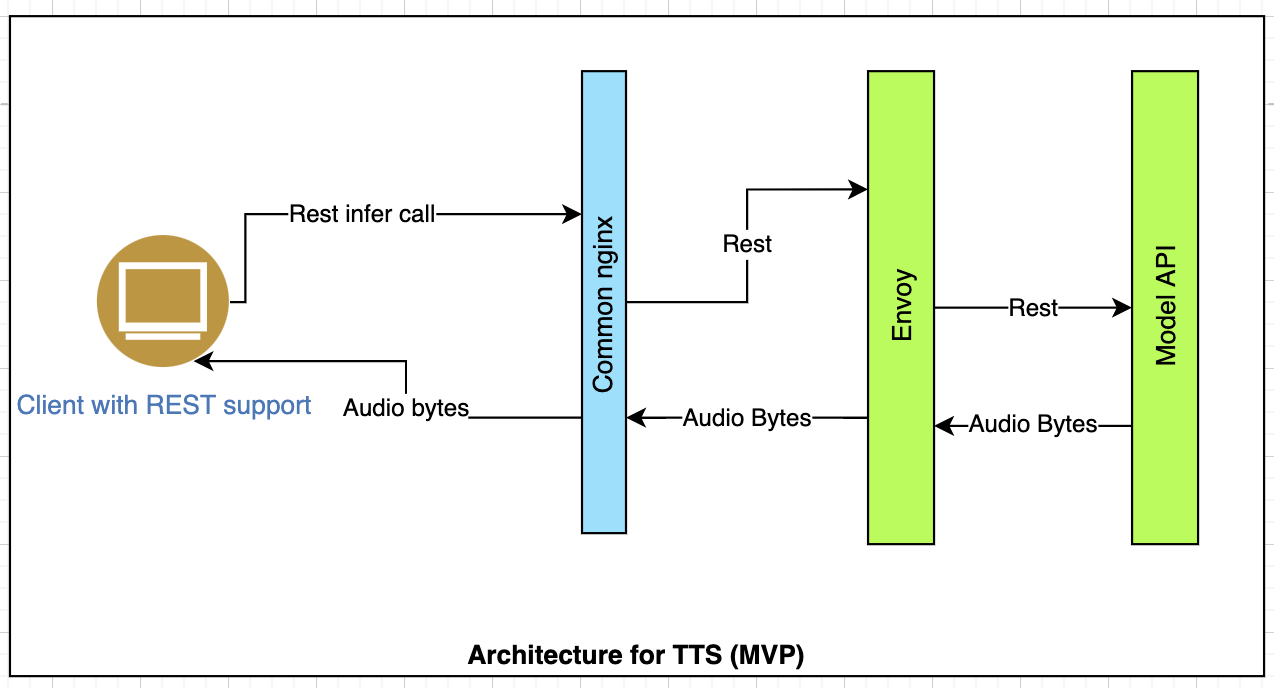
We built this REST API using Fast API that can run in any python enabled environment. We have made prebuilt docker images available to run them without dealing with code built or deploy directly on Kubernetes. The above diagram represents our internal deployment using Kubernetes. We use envoy as Load Balancer and reverse proxy to forward requests to a specific instance.
REST API request takes text and config as input and returns Audio bytes. Response Audio bytes encoded as base64. Bytes can directly be embedded in a web page using an HTML Audio tag.
API reference¶
Our API has predictable resource-oriented URLs, accepts form-encoded request bodies, returns JSON-encoded responses, and uses standard HTTP response codes, and verbs.
Base URL
http://<hostname.domain-name>/tts/v1/<language_code>
Method: POST
Headers:
[{ "key": "Content-Type", "value": "application/json", "description": "", "type": "text", "enabled": true }]
Body:
Schema for TTS request and response defined at https://github.com/ULCA-IN/ulca/blob/master/specs/model-schema.yml
Example Request Body -
{
"input": [
{
"source": "भारत मेरा देश है|"
}
],
"config": {
"gender": "female",
"language": {
"sourceLanguage": "hi"
}
}
}
The attributes input and config are the mandatory attributes for the request to process. The child attribute for input is source which should hold the text to synthesize. The child attributes for config are gender and sourceLanguage.
Responses
| Code | Description |
|---|---|
| 200 | On successful completion of the job. |
| 40X, 50X | Defined in Errors section |
Response Attributes
Body: The child attribute "audioContent" of attribute "audio" would provide the audio bytes of the synthesized speech. The response also contains Audio Format and sampling as part of the response schema. Example:
{
"audio": [
{
"audioContent": "UklGRiS4AgBXQVZFZm10"
}
],
"config": {
"language": {
"sourceLanguage": "hi"
},
"audioFormat": "wav",
"encoding": "base64",
"samplingRate": 22050
}
}
Errors
Our API uses HTTP response codes to indicate the success or failure of an API request.
| Status | Meaning | Description |
|---|---|---|
| 200 | OK | Everything worked as expected. |
| 400 | Bad Request | The request was unacceptable, often due to missing a required parameter. |
| 401 | Unauthorized | No valid API key provided. |
| 402 | Request Failed | The parameters were valid but the request failed. |
| 403 | Forbidden | The API key doesn't have permissions to perform the request. |
| 404 | Not Found | The requested resource doesn't exist. |
| 409 | Conflict | The request conflicts with another request (perhaps due to using the same idempotent key). |
| 429 | Too Many Requests | Too many requests hit the API too quickly. We recommend an exponential backoff of your requests. |
| 50X | Server Errors | Something went wrong on Stripe's end. (These are rare.) |
Implementing the api from local using Docker
Our API server can be hosted from any environment which supports Docker containers as we have pre-built images packaging the API and dependencies. Our latest container images can be pulled directly from gcr.io/ekstepspeechrecognition/text_to_speech_open_api:<version tag>
Pre-requisites:
Download all tts models in the local path using gsutil -m cp -r gs://vakyansh-open-models/tts <local path>/tts_models/ Download all transliteration models into local using gsutil -m cp -r gs://vakyansh-open-models/translit_models <local path>/translit_models/ Prepare the model_dict.json and place it in
{
"hi" : { "male_glow" : "hindi/male/glow_tts",
"male_hifi" : "hindi/male/hifi_tts",
"female_glow" : "hindi/female/glow_tts",
"female_hifi" : "hindi/female/hifi_tts" }
}
Sample docker run command:
docker run -itd -p 5000:5000 --gpus all --env languages='["hi","ml"]' -v <local path>/tts_models/:/opt/text_to_speech_open_api/deployed_models/ -v <local path>/translit_models/:/opt/text_to_speech_open_api/vakyansh-tts/src/glow_tts/tts_infer/translit_models/ gcr.io/ekstepspeechrecognition/text_to_speech_open_api:2.1.4
Once the docker container is up and running, the api can be tested from localhost on port 5000.
Contributing¶
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
License¶
Distributed under the [MIT] License. See LICENSE for more information.
Git repository¶
https://github.com/Open-Speech-EkStep/text-to-speech-open-api
Contact¶
Connect with community on Gitter
Project Link: https://github.com/Open-Speech-EkStep/text-to-speech-open-api