vakyansh-tts¶
Models¶
Our open-sourced TTS models for Indic languages are present in this repo.
Components¶
There are two models at work that convert your text to an audio. First of all, we train a glow-TTS text-to-mel model to convert text to mel spectrogram. This mel spectrogram is then passed as input to a mel-to-wav model (HiFi-GAN) which converts it to an audio.
-
Text to Mel: We use Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search proposed here. You can find the original source code implemented by the authors here.
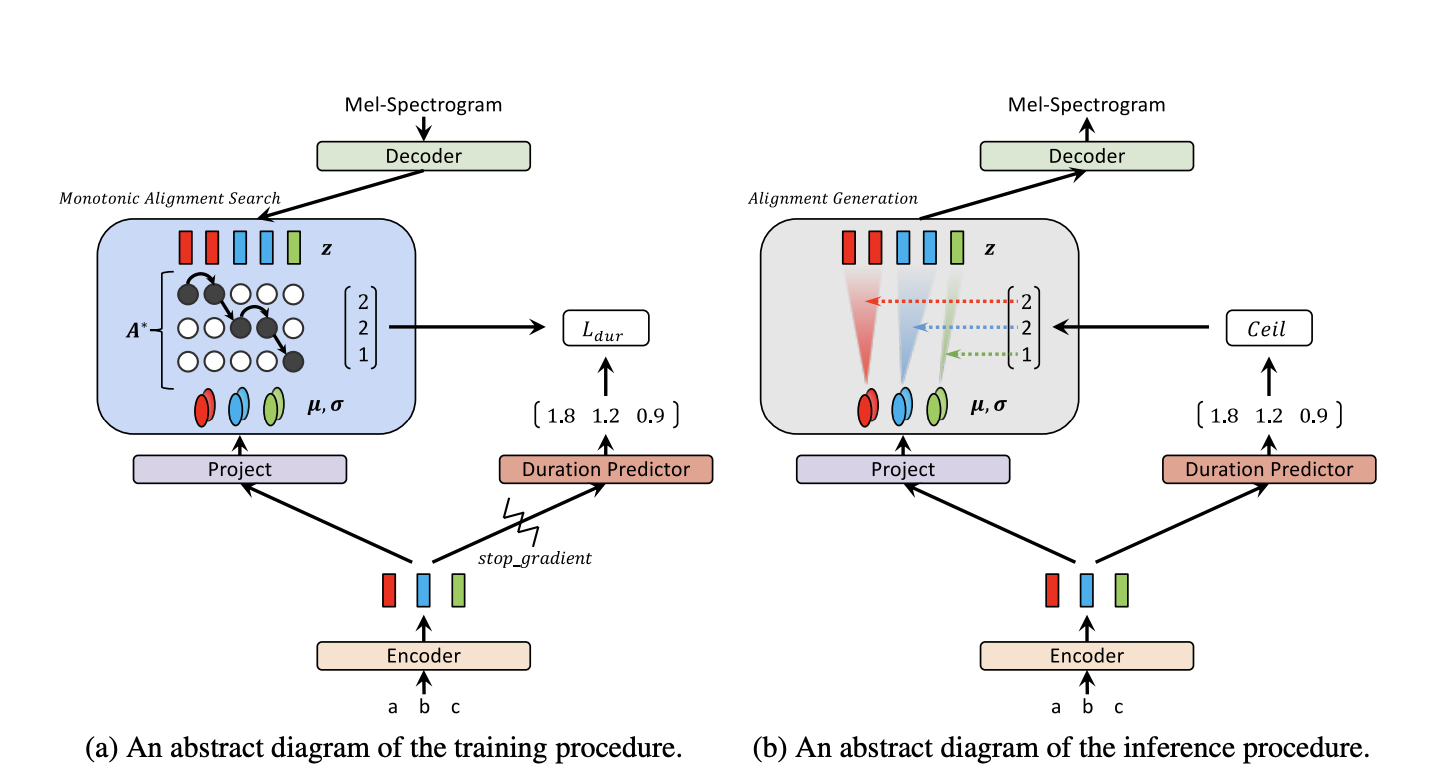
-
Mel to Wav: We use HiFi-GAN: a GAN-based model capable of generating high fidelity speech efficiently proposed here. You can find the original source code implemented by the authors here.
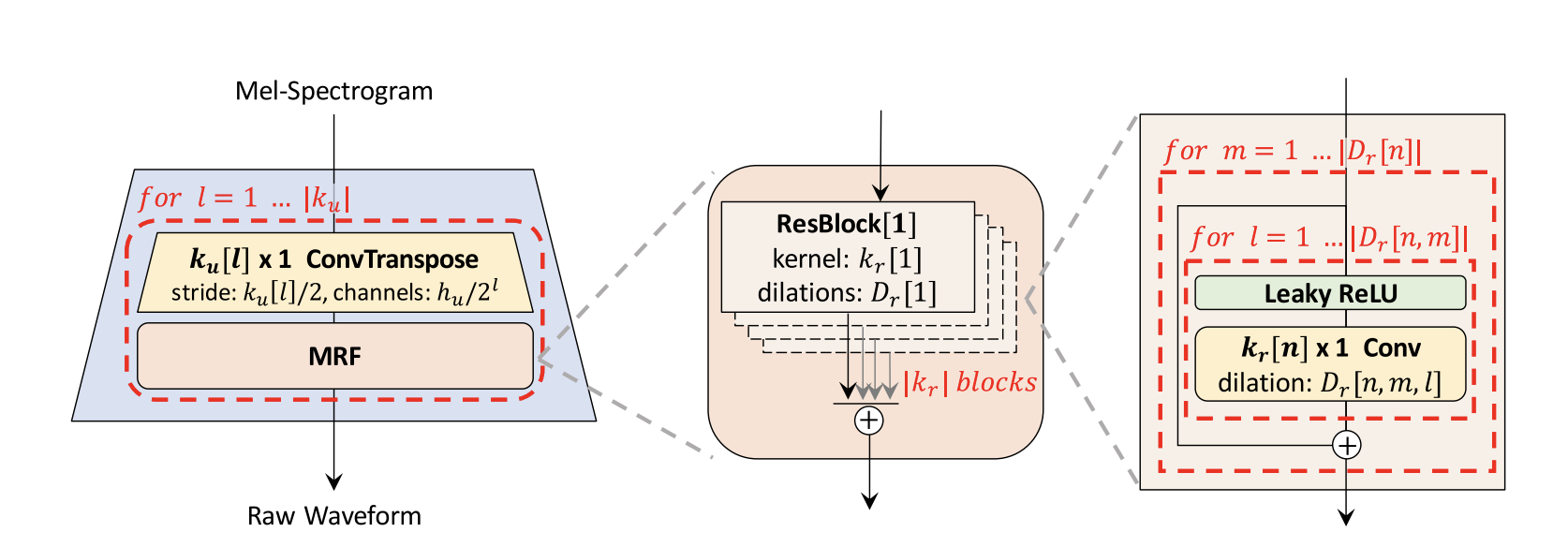
Training logs¶
Language: Hindi
Data used for training: Monolingual Hindi male corpus (4.5 hrs) from IndicCorp.
Sample Rate: 22050 Hz
Glow-TTS trained for: 100 epochs Hifi-GAN trained for: 200k steps
Tensorboard Logs¶
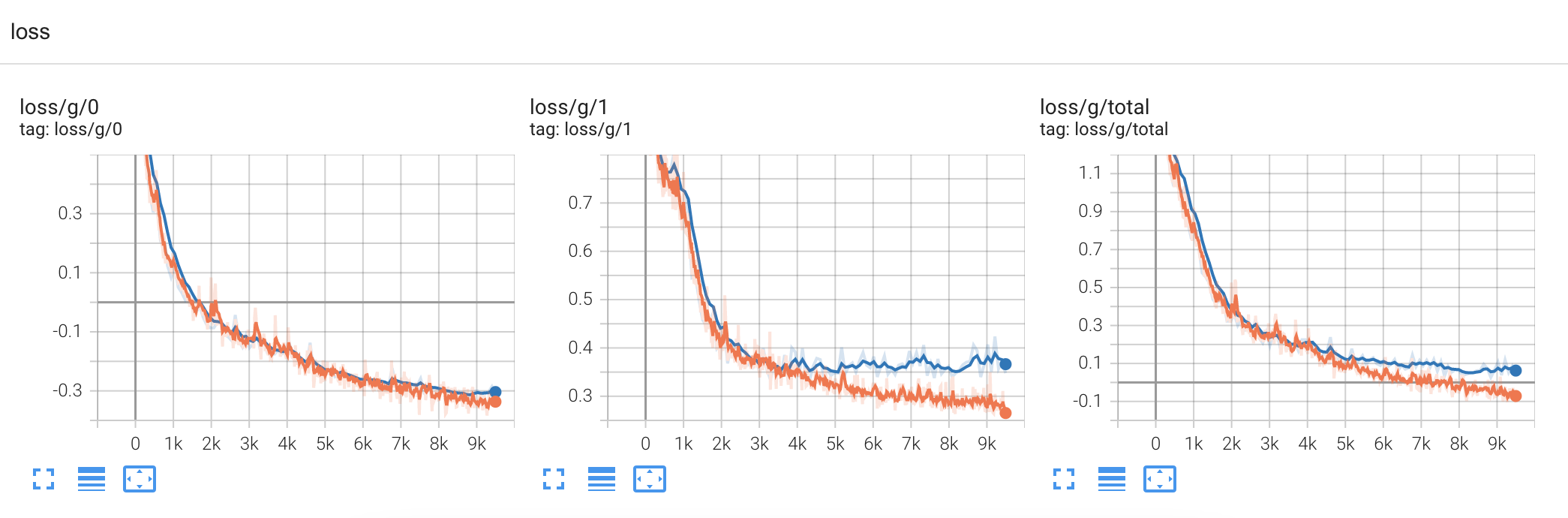
Logs for Glow-TTS training
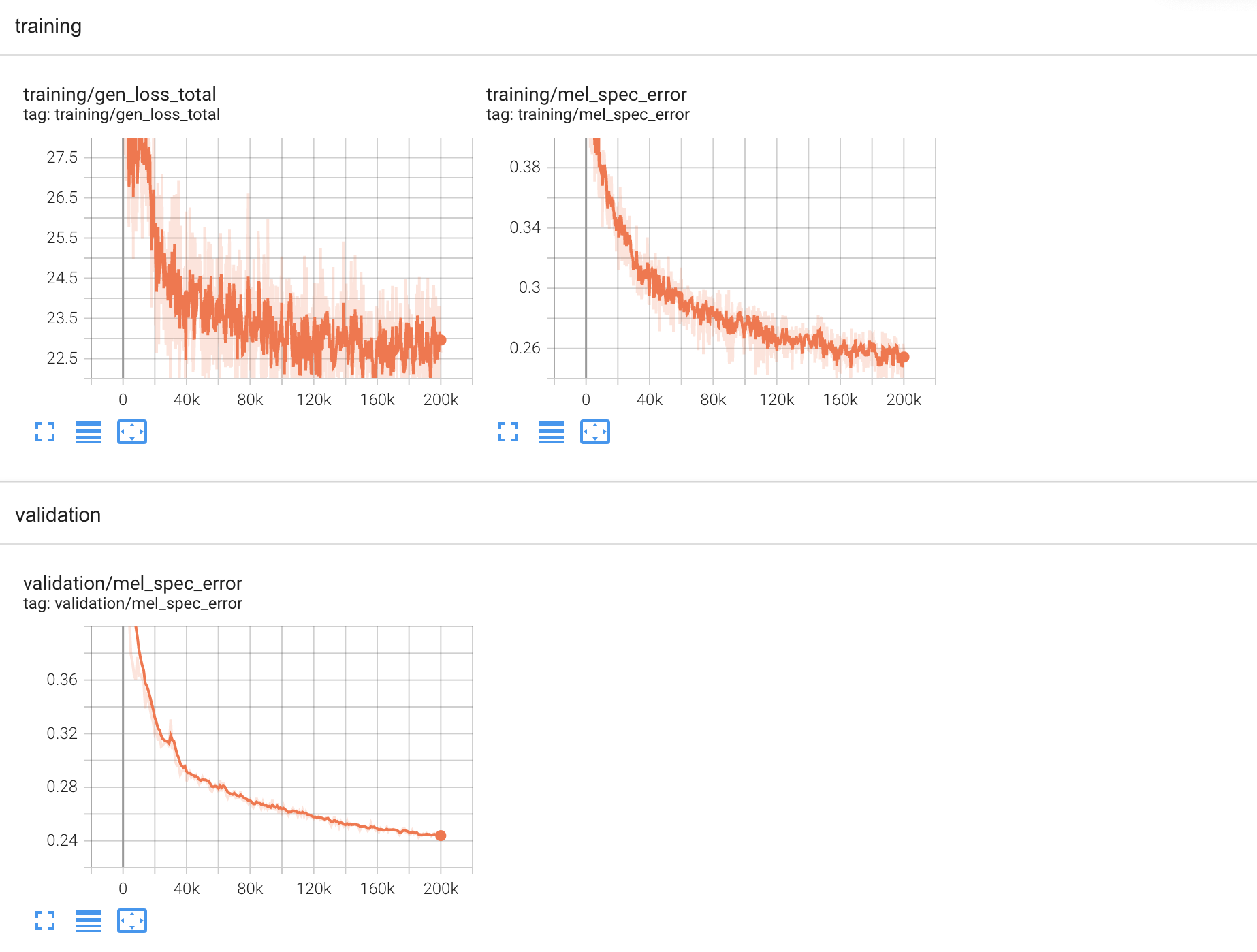
Logs for Hifi GAN training
1. Installation and Setup for training¶
Clone repo
git clone https://github.com/Open-Speech-EkStep/vakyansh-tts
git clone https://github.com/Open-Speech-EkStep/vakyansh-tts -b multispeaker
Build conda virtual environment
cd ./vakyansh-tts
conda create --name <env_name> python=3.7
conda activate <env_name>
pip install -r requirements.txt
Note: this is needed for glow-tts training
cd ..
git clone https://github.com/NVIDIA/apex
cd apex
git checkout 37cdaf4
pip install -v --disable-pip-version-check --no-cache-dir ./
cd ../vakyansh-tts
bash install.sh
2. Data Resampling¶
The data format should have a folder containing all the .wav files for glow-tts and a text file containing filenames with their sentences.
Directory structure:
langauge_folder_name
language_folder_name
|-- ./wav/*.wav
|-- ./text_file_name.txt
( audio1.wav "Sentence1." )
( audio2.wav "Sentence2." )
To resample the .wav files to 22050 sample rate, change the following parameters in the vakyansh-tts/scripts/data/resample.sh
input_wav_path : absolute path to wav file folder in vakyansh_tts/data/
output_wav_path : absolute path to vakyansh_tts/data/resampled_wav_folder_name
output_sample_rate : 22050 (or any other desired sample rate)
To run:
cd scripts/data/
bash resample.sh
3. Spectogram Training (glow-tts)¶
3.1 Data Preparation¶
To prepare the data edit the vakyansh-tts/scripts/glow/prepare_data.sh file and change the following parameters
input_text_path : absolute path to vakyansh_tts/data/text_file_name.txt
input_wav_path : absolute path to vakyansh_tts/data/resampled_wav_folder_name
gender : female or male voice
cd scripts/glow/
bash prepare_data.sh
3.2 Training glow-tts¶
To start the spectogram-training edit the vakyansh-tts/scripts/glow/train_glow.sh file and change the following parameter:
gender : female or male voice
To start the training, run:
cd scripts/glow/
bash train_glow.sh
4. Vocoder Training (hifi-gan)¶
4.1 Data Preparation¶
To prepare the data edit the vakyansh-tts/scripts/hifi/prepare_data.sh file and change the following parameters
input_wav_path : absolute path to vakyansh_tts/data/resampled_wav_folder_name
gender : female or male voice
cd scripts/hifi/
bash prepare_data.sh
4.2 Training hifi-gan¶
To start the spectogram-training edit the vakyansh-tts/scripts/hifi/train_hifi.sh file and change the following parameter:
gender : female or male voice
To start the training, run:
cd scripts/hifi/
bash train_hifi.sh
5. Inference¶
5.1 Using Gradio¶
To use the gradio link edit the following parameters in the vakyansh-tts/scripts/inference/gradio.sh file:
gender : female or male voice
device : cpu or cuda
lang : langauge code
To run:
cd scripts/inference/
bash gradio.sh
5.2 Using fast API¶
To use the fast api link edit the parameters in the vakyansh-tts/scripts/inference/api.sh file similar to section 5.1
To run:
cd scripts/inference/
bash api.sh
5.3 Direct Inference using text¶
To infer, edit the parameters in the vakyansh-tts/scripts/inference/infer.sh file similar to section 5.1 and set the text to the text variable
To run:
cd scripts/inference/
bash infer.sh
To configure other parameters there is a version that runs the advanced inference as well. Additional Parameters:
noise_scale : can vary from 0 to 1 for noise factor
length_scale : can vary from 0 to 2 for changing the speed of the generated audio
transliteration : whether to switch on/off transliteration. 1: ON, 0: OFF
number_conversion : whether to switch on/off number to words conversion. 1: ON, 0: OFF
split_sentences : whether to switch on/off splitting of sentences. 1: ON, 0: OFF
cd scripts/inference/
bash advanced_infer.sh
5.4 Installation of tts_infer package¶
In tts_infer package, we currently have two components:
1. Transliteration (AI4bharat's open sourced models) (Languages supported: {'hi', 'gu', 'mr', 'bn', 'te', 'ta', 'kn', 'pa', 'gom', 'mai', 'ml', 'sd', 'si', 'ur'} )
2. Num to Word (Languages supported: {'en', 'hi', 'gu', 'mr', 'bn', 'te', 'ta', 'kn', 'or', 'pa'} )
git clone https://github.com/Open-Speech-EkStep/vakyansh-tts
cd vakyansh-tts
bash install.sh
python setup.py bdist_wheel
pip install -e .
cd tts_infer
wget https://storage.googleapis.com/vakyansh-open-models/translit_models.zip && unzip -q translit_models.zip
Usage: Refer to example file in tts_infer/
from tts_infer.tts import TextToMel, MelToWav
from tts_infer.transliterate import XlitEngine
from tts_infer.num_to_word_on_sent import normalize_nums
import re
from scipy.io.wavfile import write
text_to_mel = TextToMel(glow_model_dir='/path/to/glow-tts/checkpoint/dir', device='cuda')
mel_to_wav = MelToWav(hifi_model_dir='/path/to/hifi/checkpoint/dir', device='cuda')
def translit(text, lang):
reg = re.compile(r'[a-zA-Z]')
engine = XlitEngine(lang)
words = [engine.translit_word(word, topk=1)[lang][0] if reg.match(word) else word for word in text.split()]
updated_sent = ' '.join(words)
return updated_sent
def run_tts(text, lang):
text = text.replace('।', '.') # only for hindi models
text_num_to_word = normalize_nums(text, lang) # converting numbers to words in lang
text_num_to_word_and_transliterated = translit(text_num_to_word, lang) # transliterating english words to lang
mel = text_to_mel.generate_mel(text_num_to_word_and_transliterated)
audio, sr = mel_to_wav.generate_wav(mel)
write(filename='temp.wav', rate=sr, data=audio) # for saving wav file, if needed
return (sr, audio)